

In the second round of ABINIT vs VASP comparison, I am using a bigger 128-atom supercell of Li2FeSiO4 with one k-point, as is customary for big supercells. Compared to the silicon supercell that was studied in round 1, this system is big enough to be able to scale well across a few nodes in a cluster. This will tell us something about the parallel scaling. These are the results using optimized settings for both VASP and ABINIT on the Matter cluster at NSC:
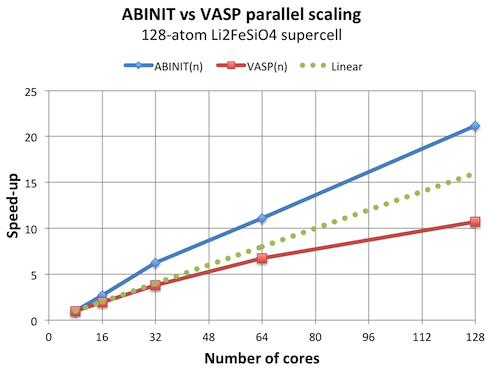
The parallel scaling of ABINIT is quite remarkable. It is superlinear for 1-4 nodes, and with 16 nodes the efficiency is still above 100%. Clearly, ABINIT is superior to VASP in terms of parallel scaling.
So should we all run ABINIT and enjoy tremendous speed-ups? The astute reader will notice that I have played a trick and only showed the normalized results. The chart above does not show the actual speed, only the parallel scaling relative to a single node run. The reason is that I want to compare to ideal linear scaling. Comparing actual speed, however, reveals another picture:
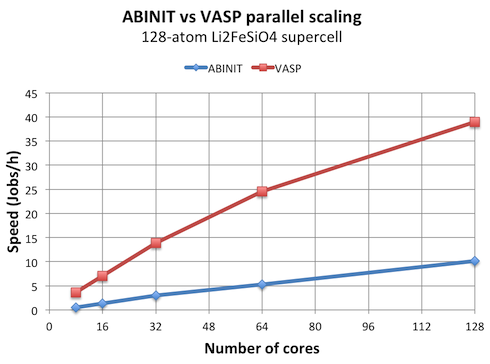
VASP is 4x faster than ABINIT, despite worse parallel scaling. It makes me wonder if I missed some setting in ABINIT that magically reduces all the data structures by half. In particular, I was expecting gamma-point only optimization options, but it does not seem to exist in ABINIT? So in order to make it at all comparable, I used the normal -DNGZhalf version of VASP. For actual calculations with the gamma-point only version, VASP would be even faster than shown here.
Parallelization settings in ABINIT
ABINIT can parallelize over k-points, spin, bands and FFTs. Here, it is just 1 k-point, and no spin polarization, so there are two influential parameters which affects parallelization: npbands and npfft. The general recommendation in the ABINIT manual is to use npbands = number of cores, and npftt=1 for runs of up to a few nodes, and to aim for npband >= 4*npfft for wide parallel runs. Just like NPAR needs to be optimized for VASP, different npband and npfft combinations should be tested for ABINIT. These are the values I found, and what I used to generate the comparison above:
| Nodes | Best combination | Speed (Jobs/h) | |
|---|---|---|---|
| 1 | npbands=8/npfft=1 | 0.48 | | |
| 2 | npbands=8/npfft=2 | 1.30 | | |
| 4 | npbands=8/npfft=4 | 3.00 | | |
| 8 | npbands=8/npfft=8 | 5.32 | | |
| 16 | npbands=8/npfft=16 | 10.13 | |
The general rule from the manual does not hold exactly here. Using only band parallelization is optimal for a single node, but once we run across nodes in the network, we need to activate the FFT parallelization for best performance. The rule seems to be:
npbands = 8 (cores per node?)
npfft = number of compute nodes
The choice can be quite influential: with 16 nodes, npband=128/npfft=1 is almost three times slower. But please keep in mind that these settings may not be universal.