

It is often claimed that VASP cannot “scale” to more than 1000 cores, but this is not entirely correct, as can be seen in the graph below.
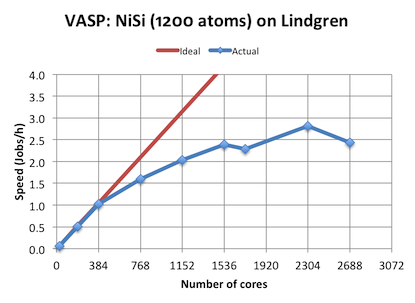
What you see are results from Lindgren, the Cray XE6 system at PDC, running a full SCF cycle on a 1200-atom NiSi surface. With 384 cores, the job requires about one hour without using too aggressive settings. This is a respectable run-time by itself, but we can also see that we can rougly triple the speed by increasing the number cores up to the plateau value of ca 2300 cores. But we pay a price for this, which is spending almost 2x more core hours in total to get the job done. So if you ask about the upper limit for VASP in terms of number of cores, the answer is that it depends the size of simulation cell, and the loss of core hours that one is willing to accept to get results quickly.
For everyday calculations, my personal preference is to use the node count where the computational efficiency drops below 50%. In this case, gettting > 50% efficiency for more than say 16 compute nodes (128-384c) is usually a challenge, even for big simulations with many hundred atoms. A small investigation of differently sized supercells revealed the following relationship:
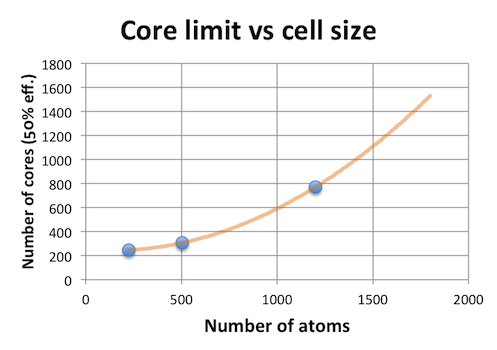
Technically, this is an example of weak scaling, where a large simulation size is necessary to get good parallel scaling. Judging by this study, we find that there is indeed no reasonably sized simulation cell where VASP can be run on > 1000 cores without poor efficiency.
But for large one-shot jobs, where time to solution is important, a lower efficiency is acceptable. There are several reasons why you would want to do this:
- You need the results fast due to a deadline, or the sequential nature of the study.
- It is the only way to get your job through due to practical wall-time limits (typically less than one week at most supercomputing center).