

I finally got around to run some VASP benchmarks on the recently released Intel Xeon E5 v3-processors (see previous post for an overview of the differences vs older Xeon models). I have tested two different configurations:
- A 16-core node from the coming weather forecasting cluster at NSC to be named “BiFrost”. It is equipped with the Xeon E5-2640v3 processor at 2.6 Ghz, together with 64 GB of 1866 MHz DDR4 memory.
- The 32-core nodes in the Cray XC40 “Beskow” at machine at PDC. The processor model is Xeon E5-2698-v3. Beskow also has two sockets per node with 64 GB memory, but the speed of the memory is faster: 2133 MHz.
I did a quick compile of VASP with Intel Fortran (version 14 and 15) and ran some single node benchmarks of the 24-atom PbSO4 cell I traditionally use for initial testing.
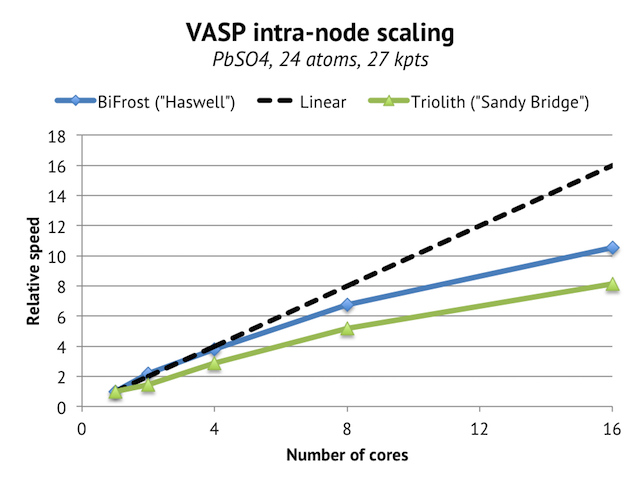
The initial results are basically along my expectations. The single core performance is very strong thanks to Turbo Boost and the improved memory bandwidth. It is the best I have measured so far: 480 seconds vs 570 seconds earlier for a 3.4 Ghz Sandy Bridge CPU.
When running on all 16 cores and comparing to a Triolith node, the absolute speed is up 30%, which is also approximately +30% improved performance per core, as the number of cores are the same and the effective clock frequency is also very close in practice. The intra-node parallel scaling has improved as well, which is important, because it hints that we will be able to run VASP on more than 16 cores per node without degrading performance too much on multi-core nodes such as the ones in Beskow. In fact, when running the above cell on a single Cray XC-40 node with 32-cores, I do see improvement in speed all the way up to 32 cores:
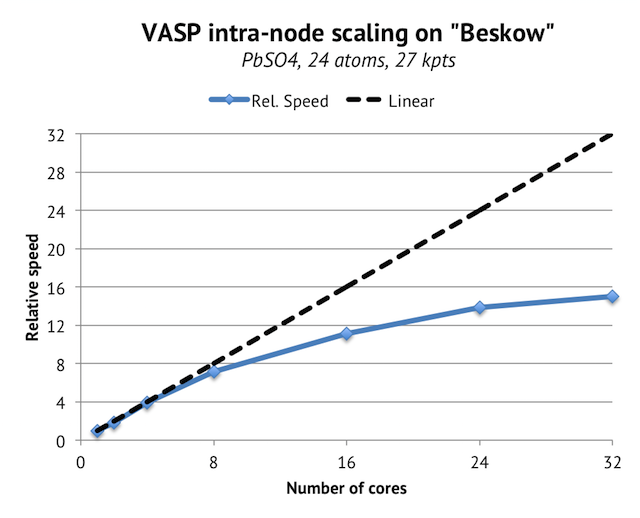
This is a good result, since the paralllel scaling for such a small cell is not that good in the first place.
So overall, you can expect a Beskow compute node to be about twice as fast as a Triolith node when fully loaded. That is logical, as it has twice as many cores, but not something that you can take for granted. However, when running wide parallel jobs, I expect you are likely to find that using 24 cores/node is better, because 24-cores brings 90+% of the potential node performance, while at the same significantly lowering the communication overhead due to having many MPI processes.
A first case study: a 512-atom supercell
I will publish more comprehensive benchmarks later, but here is an indication of what kind of improvement you can expect on Beskow vs Triolith for more realistic production jobs. The test system is a 512-atom GaAs supercell with one Bi defect atom. A cell like this is something you would typically run as part of a convergence study to determine the necessary supercell size.
- Using 64 compute nodes on Triolith (1024 cores in total) it takes 340s to run a full SCF cycle to convergence (13 iterations)
- On Beskow, using 64 compute nodes and 1536 cores (24c/node), it takes 160s.
Again, about 2.0x faster per compute node. If you compare it to the old Cray XE6 “Lindgren” at PDC, the difference will be even bigger, between 3-4x faster. But please keep in mind that allocations in SNIC are accounted in core hours, and not node hours, so while your job will run approximately twice as fast on the same number of nodes, the “cost” in core hours is the same.