

VASP is a popular implementation of the projector augmented wave method (“PAW”). The most important reason for using VASP is likely to get access to their PAW atomic data set library (“POTCARs”), but what about the speed? My first test system is a 31 atom silicon supercell (with one vacancy).
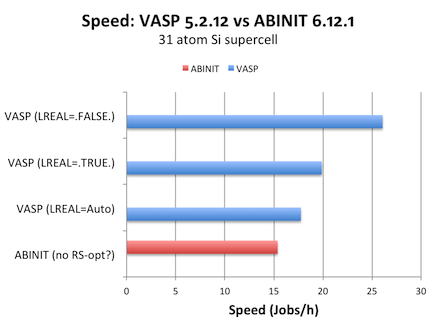
Conclusion: My VASP calculation runs about 1.7x faster than ABINIT for this system. I was using one compute node (8 cores) on the Kappa cluster.
The real space optimization (“RSO”) scheme turned out to be a significant factor. It is not so efficient for this cell, which we can see by turning it off for VASP. In case of ABINIT, I am uncertain whether it was used or not – I find no mention of RSO in the manual, and the tutorials imply that this option has to be enabled when generating the atomic data file. Inspecting the file on the ABINIT website Si_GGA_input suggests it was not used. It is therefore reasonable to compare vs VASP with LREAL=.FALSE. (no real space evaluation).
Caveat: I am an experienced VASP user, but not so experienced with ABINIT. Still, I took great care to make sure that the settings are comparable, and the intention is to gain knowledge of ABINIT tuning while continuing this project.
For reference, the settings were:
| Parameter | VASP | ABINIT | |
|---|---|---|---|
| Plane-wave basis set cut-off | 250 eV | 250 eV | | |
| Main FFT grid | 723 | 723 | | |
| Fine FFT grid | 1443 | 1443 | | |
| FFT algorithm | Intel MKL | Goedecker “401” | | |
| Bands | 80 | 80 | | |
| Electrons | 124 | 124 | | |
| K-points | 6 | 6 | | |
| Parallelization | NPAR=1 | npband=8/npfft=1 | | |
| SCF algorithm | ALGO=Fast | wftoptalg=14 | | |
| SCF mixing | default | iscf=17 | | |
| Mixing accuracy | LMAXMIX=2 | pawlmix=2 | | |
| Real space optimization | varied | no? | |
I believe that the most significant difference was that the ABINIT calculation converged in 9 SCF steps vs 15 in VASP, presumably due to a better mixing scheme. On the other hand, being able to use FFTs from Intel’s MKL in VASP should improve the speed significantly (I have seen it give speed boosts of ca. 25% vs FFTW for smaller systems on Intel processors.)