

I did some more testing of BLAS and FFT libraries for VASP on Cray XE6, while working on VASP 5.3.3 for PDC’s Lindgren. Before, I always prepared VASP with Intel MKL and Cray MPI. This was mostly for compatibility reasons, but benchmarking also showed that the MKL version was much faster (ca 10%-20%) than the LibSci version. It is counterintuitive, since Cray has optimized BLAS routines in LibSci (in addition to the standard ones from GotoBLAS). Why was MKL so much faster? Could it be the FFT subroutines, just like what I saw on Sandy Bridge cpu:s? I decided to build a version of VASP with BLAS/LAPACK from LibSci and FFTs from Intel’s MKL to test this hypothesis. For reference, the LibSci version was 11.1, and the MKL version the one included in PrgEnv-intel/4.0.46, i.e. 10.3.
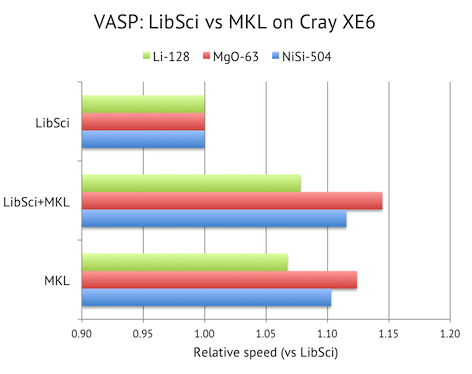
I ran three test systems:
- Li2FeSiO4 cell with 128 atoms, standard DFT, with 2 compute nodes.
- MgO cell with 63 atoms using HSE06 and k-point parallelization over 3 compute nodes.
- NiSi cell with 504 atoms over 16 compute nodes (384 cores), standard DFT.
The MKL version is indeed faster than the LibSci version, +7-12%, but it is possible to squeeze out a few % more performance by combining LibSci with MKL. The system jitter on Lindgren is normally very low , so the differences here are statistically significant. So, for the 5.3.3 version, I decided to deploy the LibSci+MKL version on Lindgren.