

This week we are running a course in parallel programming with OpenMP at NSC. Joachim Hein from LUNARC is teaching and a few of us from NSC are helping out with the programming labs.
It is often said that parallel programming can be incredibly hard, and that there is currently no reliable way to automatically parallelize an existing serial program. This statement is still true in general, but sometimes, parallel programming can also be embarrassingly easy. Why? Because while automatic parallelization is not perfect, it can still give you some improvement. There are also many subroutines in BLAS, LAPACK and FFTW that are already parallelized, and since many programs rely on these libraries, they can see speed-up on multicore processors by just linking the right library version and setting OMP_NUM_THREADS=X in the shell.
Let us consider the Elk FP-LAPW code . It is written in Fortran90, and has already been parallelized using both OpenMP and MPI. But what could we have done in the hypothetical case of starting out with the serial version of Elk? How good is automatic parallelization? It will surely not get us all the way, but every percent counts, because you essentially get it for free. It is merely a question of finding the relevant compiler flags.
To establish a baseline, I have Elk compiled without any special compiler flags or machine-optimized numerical libraries. This may seem naive and unrealistic, but in reality, it is not uncommon to come across scientific software built without any compiler optimizations flags or optimized linear algebra libraries such as GotoBLAS, MKL, or ATLAS. (In my experience, it is not so much a result of ignorance, but rather technical problems with compilation and/or lack of time for tinkering.)
The test case I am using is the YBCO example distributed with Elk (13 atoms) with the rgkmax parameter increased to 7.0 to get longer runtime.
The first step in our hypothetical example is to simply add “-O3” optimization. This gives us 9% speed boost. The next crucial step is to replace the bundled BLAS, LAPACK and FFT libraries with Intel’s MKL libraries, which improves the speed by 27%. And finally, we activate the compiler’s automatic threaded parallelization, which gives us +80%. The results can then be compared with the production version of Elk for Triolith, which uses aggressive compiler optimizations, MKL libraries, and has manual OpenMP parallelization.
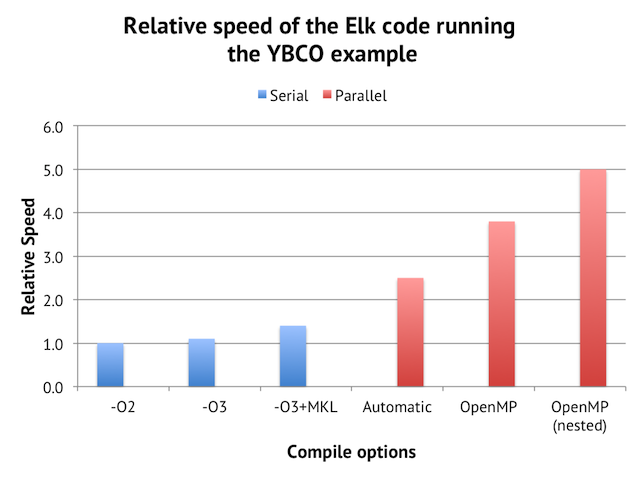
We can see that automatic parallelization gives a modest speed-up of 1.7x using 16 cores on a Triolith compute node. Still, this is not too bad compared with the OpenMP parallelized version which gets 5.0x over the serial version in total, but only 2x of that is actually due to the OpenMP constructs in the code. So essentially, we get half of the parallelization done automatically for free, without having to change any Fortran code.
Another way of looking at this graph is that it can really pay off to spend some time looking into the best way to compile and link a program. The optimized auto-parallel version is 2.5x faster than the naive version built just from the Elk source with integrated numerical libraries.
Most of tricks I used to compile Elk in this example are listed in the Triolith User Guide. If you encounter problems compiling your own program on Triolith, or need help with choosing the best libraries, please don’t hesitate to contact support@nsc.liu.se.