

This is the first post in a series about VASP tuning. Optimized Fast Fourier transform subroutines are one of the keystones of getting a fast VASP installation. When I did a similar study for the Matter cluster at NSC (which has Intel “Nehalem” processors) in 2011, I found that MKL was superior. Now, it is time to look at Triolith, which has processors of “Sandy Bridge” architecture. These processors have new 256-bit vector instructions (called “AVX”), which need to be exploited for maximum floating-point performance.
Basically, we have three choices of FFTs:
- VASP’s built-in library by Jürgen Furthmüller, called “FURTH”. It is quite old now, but has the advantage that it comes with the VASP code, so that we don’t have to rely on an external library; we can also recompile it for new architectures. For best performance, one have to optimize the CACHE_SIZE precompiler flag (usually a value between 0-32000).
- The classical FFTW library. It can be optimized for many architectures by an automatic procedure. FFTW has support for AVX since version 3.3.1. On Triolith, we currently have version 3.3.2.
- Intel’s own Math Kernel Library (“MKL”). Presumably, noone should be better at optimizing for Intel processors than Intel themselves? Intel is also very aggressive with processor support, and many times MKL has support for unreleased processors. MKL gained AVX support in version 10.2, but version 10.3 and higher uses AVX instructions automatically.
I chose the PbSO4 cell with 24 atoms as the test system, as it is quite small and more reliant on good FFT performance. Here are the results, without much further ado:
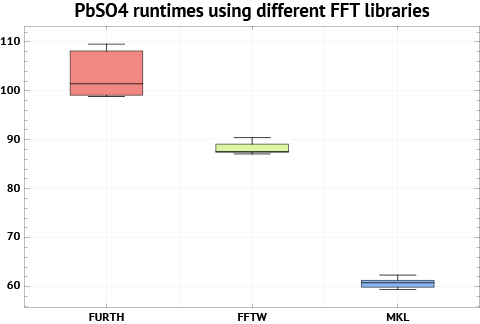
We can see that MKL 10.3 is the best choice here, with an average runtime of 61 seconds, 45% faster than FFTW 3.3.2. The results for FFT-FURTH does not come out well. I think one reason is that this library does not utilize AVX instructions fully on Sandy Bridge. The default optimization options in the makefile are very conservative (-O1/-O2), so we will not get the full benefit. It might be possible to compile it more aggressively and get better speed.