

I have gotten requests about benchmarks of smaller simulations, rather than big supercells with hundreds of atoms. Below are the results for an 8-atom FeH cell with 64 bands and 400 k-points. Remember that VASP does not have parallelization over k-points, so it is very challenging to get good parallel performance in this case. Based on the good rule of thumb of using no more than 1 core per atom, or 4 bands per core, one should expect parallel scaling only within a compute node with 16 cores, but nothing beyond that.
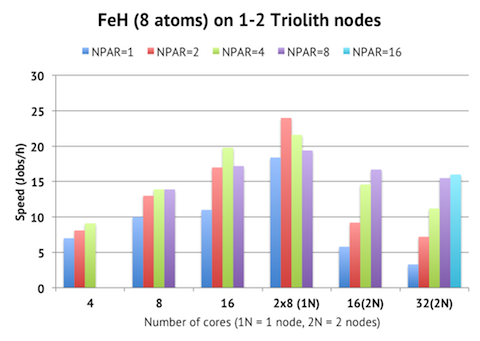
This is also what I see when running full NPAR/NSIM tests with 4-32 ranks, as seen in the chart. Peak performance is achieved with 16 cores on one compute node, using NPAR=4. Using two compute nodes is actually slower, even when using the same number of MPI ranks. This implies that the performance is limited by communication and synchronization costs, and not by memory bandwidth (otherwise we would have seen an improvement in speed when using 16 ranks on two nodes instead of one.) An interesting finding is that if you are submitting many jobs like this in queue and are mainly interested in throughput rather than time to solution, then the optimal solution is to run two 8-core jobs on the same compute node.
The NSIM parameter does not seem to be as influential here, because we have so few bands. The full table is shown below:
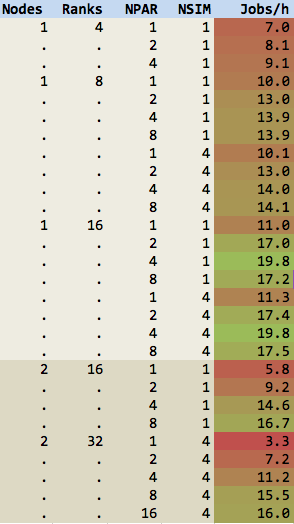
I also checked the influence of LPLANE=.FALSE. These results are not shown, but the difference was within 1%, so it was likely just statistical noise.