

VASP 5.3.2 finally introduced official support for k-point parallelization. What can we expect from this new feature in terms of performance? In general, you only need many k-points in relatively small cells, so up front we would expect k-point parallelization to improve time-to-solution for small cells with hundreds or thousands of k-points. We do have a subset of users at NSC, running big batches of these jobs, so this may be a real advantage in the prototyping stage of simulations, when the jobs are set up. In terms of actual job throughput for production calculations, however, k-point parallelization should not help much, as the peak efficiency is reached already with 8-16 cores on a single node.
So let’s put this theory to test. Previously, I benchmarked the 8-atom FeH system with 400 k-points for this scenario. The maximum throughput was achieved with two 8-core jobs running on the same node, and the time-to-solution peaked at 3 minutes (20 jobs/h) with 16 cores on one compute node. What can k-point parallelization do here?
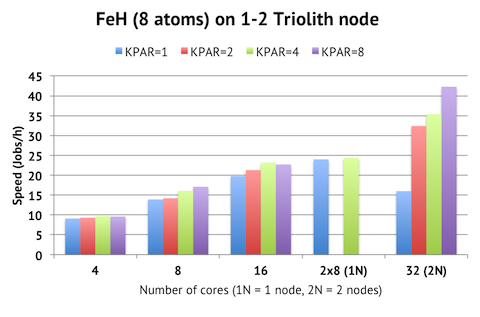
KPAR is the new parameter which controls the number of k-point parallelized groups. KPAR=1 means no k-point parallelization, i.e. the default behavior of VASP. For each bar in the chart, the NPAR value has been individually optimized (and is thereby different for each number of cores). Previously, this calculation did not scale at all beyond one compute node (blue bars), but with KPAR=8 (purple bars), we can get close to linear (1.8x) speed-up going from 1 to 2 nodes, cutting the time-to-solution in half. As suspected, in terms of efficiency, the current k-point parallelization is not more efficient than the old scheme when running on a single node, which means that peak throughput remains the same at roughly 24 jobs/h per compute node. This is a little surprising, given that there should be overhead associated with running two job simultaneously on a node, compared to using k-point parallelization.
What must be remembered, though, is that it is considerably easier to handle the file and job management for several sequential KPAR runs vs juggling several jobs per node with many directories, so in this sense, KPAR seems like a great addition with respect to workflow optimization.